
As Large Language Models (LLMs) and agentic AI systems scale, traditional relational databases are no longer sufficient for handling the massive influx of unstructured data. To build intelligent applications that understand context, developers need a storage solution designed specifically for semantic meaning.
- The Core Concept: What are Vector Embeddings?
- How Do Vector Databases Work? (Under the Hood)
- Vector Databases vs. Traditional Relational Databases
- Key Algorithms and Distance Metrics
- Why Vector Databases are Essential for Generative AI
- Top Vector Databases in the 2026 Cloud Ecosystem
- Real-World Use Cases Beyond Chatbots
- Frequently Asked Questions (FAQ)
- Conclusion & The Future of Data Storage
What is a vector database? A vector database is a specialized storage system designed to index, store, and query high-dimensional vector embeddings. Instead of querying data by exact keyword matches (like SQL), vector databases use similarity search algorithms to retrieve information based on context, semantic meaning, and visual similarity.
The Core Concept: What are Vector Embeddings?
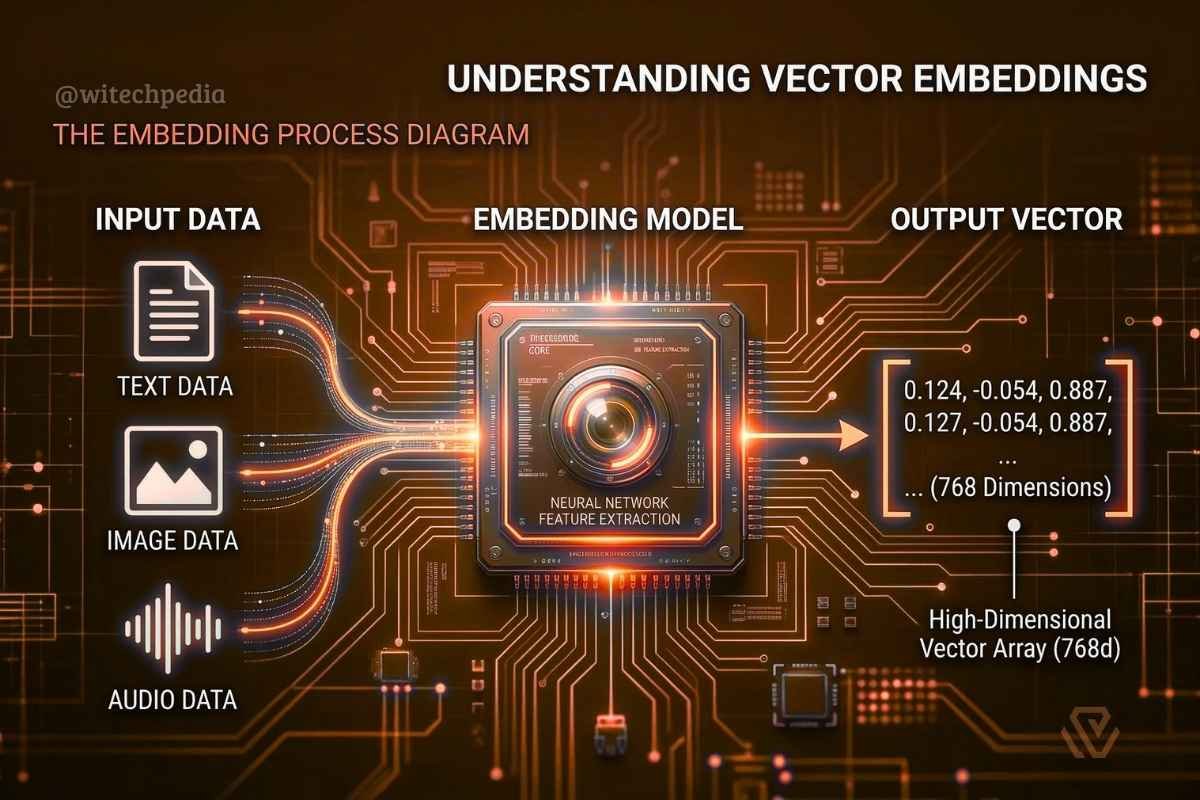
Before understanding the database, you must understand the data it stores. AI models do not understand English text, raw audio, or pixels. Instead, they convert unstructured data into numerical arrays called vector embeddings.
When you pass a sentence, a document, or an image through an embedding model (like OpenAI’s text-embedding-3-small), the output is a continuous array of floating-point numbers. These numbers map the fundamental “meaning” of the data. In the context of Multimodal AI, this means a text description of a dog and a JPEG of a dog can share a mathematically similar location in space.
How Do Vector Databases Work? (Under the Hood)
Traditional databases search for exact matches (SELECT * WHERE keyword = 'cloud'). Vector databases search for proximity.
1. High-Dimensional Space
Vector embeddings do not live on a simple X/Y axis. They exist in high-dimensional space—often spanning 384, 1536, or even 4096 dimensions depending on the model. Each dimension represents a granular feature of the data’s semantic meaning.
2. Similarity Search
When a user submits a query, the application converts that query into a vector using the exact same embedding model. The vector database then performs an Approximate Nearest Neighbor (ANN) search to find the stored vectors that are mathematically closest to the query vector.
Vector Databases vs. Traditional Relational Databases
| Feature | Relational Databases (SQL) | Vector Databases |
| Data Type | Structured (Rows, Columns) | Unstructured (Text, Images, Audio) |
| Storage Format | Tables and primitive data types | High-dimensional floating-point arrays |
| Query Method | Exact keyword/value match | Semantic similarity / Contextual proximity |
| Indexing Mechanism | B-Trees, Hash Indexes | ANN, HNSW, IVF-PQ |
| Best Use Case | Financial records, User accounts | Generative AI, Semantic Search, Recommendation Engines |
Key Algorithms and Distance Metrics
To determine which vectors are “closest” to a query, vector databases use specific mathematical distance metrics.
Distance Metrics
1. Cosine Similarity
This is the most common metric used in NLP and document retrieval. It measures the cosine of the angle between two vectors, focusing on the direction rather than the magnitude.
Or expanded:
= ∑(Ai × Bi) / [ √∑(Ai2) × √∑(Bi2) ]
A score of $1$ means the vectors are pointing in the exact same direction (highly similar).
2. Euclidean Distance (L2)
L2 measures the straight-line distance between two points in the vector space. It is highly sensitive to the magnitude of the vectors.
3. Dot Product
This measures both the angle and magnitude of the vectors. It is highly efficient for hardware-level calculations when vectors are normalized.
Indexing Algorithms (HNSW & IVF)
Searching a database of a billion vectors by calculating the distance to every single one (K-Nearest Neighbors or KNN) is computationally impossible for real-time applications. Instead, vector databases use Approximate Nearest Neighbor (ANN) algorithms:
Why Vector Databases are Essential for Generative AI
Powering Retrieval-Augmented Generation (RAG)
Vector databases act as the “long-term memory” for LLMs. Through a Retrieval-Augmented Generation (RAG) pipeline, a vector database securely stores proprietary company data. When a user asks a question, the database retrieves the most relevant embedded chunks and feeds them to the LLM as context, eliminating the need to fine-tune the model.
Eliminating AI Hallucinations
Because vector databases ground the AI’s response in factual, retrieved data chunks, they drastically reduce hallucinations and ensure high-fidelity outputs for enterprise applications.
Top Vector Databases in the 2026 Cloud Ecosystem
When architecting a cloud data strategy, developers have several tiers of vector databases to choose from:
Real-World Use Cases Beyond Chatbots
While chatbots and AI agents are the primary drivers, vector databases power much more:
Frequently Asked Questions (FAQ)
Can I use SQL with a vector database?
Pure vector databases do not natively use SQL. However, hybrid databases like PostgreSQL (via the pgvector extension) allow you to run standard SQL queries alongside vector similarity searches.
Is a vector database a NoSQL database?
Yes, vector databases are categorized under the NoSQL umbrella because they do not rely on relational schemas or tabular structures. They are built entirely around storing and indexing high-dimensional arrays.
What is the difference between a graph database and a vector database?
A graph database (like Neo4j) stores data based on explicit, predefined relationships and nodes (e.g., “User A is friends with User B”). A vector database stores data based on implicit mathematical similarities, discovering relationships that were never explicitly defined.
Conclusion & The Future of Data Storage
Vector databases have transitioned from niche machine learning tools to foundational elements of modern web architecture. As multimodal models become more accessible, the ability to store, index, and retrieve complex embeddings at millisecond latency will be a required skill for any software engineer.